https://www.cnblogs.com/orlion/p/5765339.html
https://zhuanlan.zhihu.com/p/627238135
https://blog.csdn.net/a513247209/article/details/118326530
https://zhuanlan.zhihu.com/p/502146080?utm_id=0
https://riscv-programming.org/book/riscv-book.html
https://toolchains.bootlin.com/
https://blog.csdn.net/dmf_fff/article/details/130937975
https://blog.csdn.net/hy907539007/article/details/102608816/
https://www.cnblogs.com/harrypotterjackson/p/17548837.html
汇编语法
Label、Symbols、reference、relocation
- 标签:它是一种标记,指示程序的位置。或者说定义了例程(
routine)的入口点(entry poin)。其声明以":"的后缀结束
x:
.word 10
sum10:
lw a0, x
addi a0, a0, 10
ret这里的“x”是一个label,他是一个地址,而“sum10”也是一个label,它是一段程序的地址。所以标签并不区分变量或者函数。
- 符号:程序符号是与数值相关联的“名称”,而“符号表”是将每个程序符号映射到其值的数据结构。
使用“.set”可声明一个符号
lable可自动的转换为symbol通过将汇编与表示其地址的一系列数值联系起来。
$ riscv64-unknown-elf-nm sum10.o# 符号表
000000004 t .L
000000004 t sum10
000000000 t x- 引用:每个引用标签必须在“组装”程序或者链接时被替换成一个地址。
trunk42:
li t1, 42
bge t1, a0, done
mv a0, t1
done:
ret这里的bge t1, a0, done就是一种引用。在链接时,需要将done替换为地址。
- 重定址(
Relocation):它是一种处理方式,将程序与代码重新分配地址。重定址表是一种数据结构,包含了描述如何去对程序指令和数据进行重新分配地址的信息。
# 使用如下命令查看重定址表
$ riscv64-unknown-elf-objdump -r trunk.otrunk.o: file format elf32-littleriscv
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
00000004 R_RISCV_BRANCH done可以看到,beg t1, a0, done中调用了done,所以done被重定向了。类型为:R_RISCV_BRANCH
接着来看看先前的程序被link,我们使用链接器产生trunk.x文件。接着使用如下命令来看看trunk.x里面的内容。
# 链接生成trunk.x
$ riscv64-unknown-elf-ld -m elf32lriscv trunk.o -o trunk.x
$ riscv64-unknown-elf-objdump -D trunk.xtrunk.x: file format elf32-littleriscv
Disassembly of section .text:
00010054 <trunk42>:
10054: 02a00313 li t1,42
10058: 00a35463 bge t1,a0,10060 <done>
1005c: 00030513 mv a0,t1
00010060 <done>:
10060: 00008067 ret
...可以看到,trunk42被链接器(linker)重新配置了地址。
- 未定义引用(
undefined references)
之前的讨论中,我们大多数的汇编代码都依赖于一个引用到程序地址的标签。但现在,如果引用的是不在本文件里的标签。通常情况是:当援引一个例程时,它可能是在其他文件实现的或者说读取一个定义在其他文件的全局变量。看看下面的代码main.s:
# Contents of the main.s file
start:
li a0, 10
li a1, 20
jal exit这里的程序调用了exit,所以在符号表中exit被设为未定义符号。通过nm(riscv64-unknown-elf-nm)工具我们可看到exit符号名前面被放置了一个‘U’:
$ riscv64-unknown-elf-nm main.o
00000000 t start
U exit汇编器(assembler)同时还会将该引用注册到重定址表中。通过objdump我们可以看到main.c文件记录了jal指令引用exit标签。
$ riscv64-unknown-elf-objdump -r main.omain.o: file format elf32-littleriscv
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
00000008 R_RISCV_JAL exit当linker(链接器)链接这些文件(*.o)时,linker会解析未定义的符号通过调整符号地址。在前面的例子中,连接器会寻找exit的地址,所以他会调整jal的地址。如果没找到,他就会打印一条错误信息。
$ riscv64-unknown-elf-ld -m elf32lriscv main.o -o main.x
riscv64-unknown-elf-ld: warning: cannot find entry symbol start; ...
riscv64-unknown-elf-ld: main.o: in function ‘start’:
(.text+0x8): undefined reference to ‘exit’这里的reference可以翻译成:标记。整句话可以翻译为:未定义标记"exit"。
全局与局部符号(Global Vs Local symbols)
符号分两种:
- 全局:全局与局部相反。可以任意地方,任意文件调用。
- 局部:只能同一个文件调用。换句话说就是,链接器无法再其他文件使用该文件的局部变量。
通常情况,汇编器会将标签定义为局部变量。而.globl可直接将标签设置为全局符号。来看看下面的全局定义:
# Contents of the exit.s file
.globl exit
exit:
li a0, 0
li a7, 93
ecall假设调用exit的代码放在main.s中,而exit函数代码放在exit.s中,那么下面的编译:
$ riscv64-unknown-elf-as -march=rv32im main.s -o main.o
$ riscv64-unknown-elf-as -march=rv32im exit.s -o exit.o
$ riscv64-unknown-elf-ld -m elf32lriscv main.o exit.o -o main.x
riscv64-unknown-elf-ld: warning: cannot find entry symbol start; ...现在链接器不在打印错误了。
程序入口(The program entry point)
每个程序都有一个入口点,即,一个CPU必须从该位置开始执行的位置。一个可执行文件的头包含了很多信息,其中一个就是入口地址。操作系统将可执行文件调入到内存中,并且设置PC指针指向该entry point开始执行。
链接器的任务就是为可执行文件设置一个入口地址,他会寻找一个start的符号。如果找到了该符号,则将其设置设置为entry point。否则的话,他会设置默认值为入口地址,通常是程序的第一条指令。
为了选择程序入口点,编程者需要再第一条指令执行前就要定义start,但是在之前的例子中我们可以看到这样的警告:warning: cannot find entry symbol start; defaulting to ...010054。这里没有找到start,所以使用默认地址。原因是因为start没有定义为全局符号,修改如下:
# Contents of the main.s file
.globl start
start:
li a0, 10
li a1, 20
jal exit^8fa213
现在编译与连接就不再出现问题了:
$ riscv64-unknown-elf-as -march=rv32im main.s -o main.o
$ riscv64-unknown-elf-as -march=rv32im exit.s -o exit.o
$ riscv64-unknown-elf-ld -m elf32lriscv exit.o main.o -o main.x 注意到我们将exit.o放在了main.o的前面,由于这样,会导致exit.o的内容放在了main.o内容的前面,我们可以通过观察main.x文件观察到:
$ riscv64-unknown-elf-objdump -D main.x
main.x: file format elf32-littleriscv
Disassembly of section .text:
00010054 <exit>:
10054: 00000513 li a0,0
10058: 05d00893 li a7,93
1005c: 00000073 ecall
00010060 <start>:
10060: 00a00513 li a0,10
10064: 01400593 li a1,20
10068: fedff0ef jal ra,10054 <exit>
... 即便是这样(exit在最前面),代码还是会将start标签设置为程序入口。
通过readelf(riscv64-unknown-elf-readelf )工具可以查看elf文件信息,注意entry point地址被设置为0x10060,即为start标签的地址:
$ riscv64-unknown-elf-readelf -h main.x
ELF Header:Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2’s complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: RISC-V
Version: 0x1
Entry point address: 0x10060
Start of program headers: 52 (bytes into file)
Start of section headers: 476 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 1
Size of section headers: 40 (bytes)
Number of section headers: 6
Section header string table index: 5程序段(Program sections)
可执行文件、对象文件和汇编程序通常按
section编排。一个section可能包含了数据与指令,和每个section被映射到主存上的内容。下面的section是Linux-based系统中可执行文件的常用的section:
.text:用来指示存储编程指令的section.data:用来指示已初始化的全局变量,即该变量的值需要再使用它之前就已经赋值了。.bss:用来储存未初始化的数据。.rodata:指示储存的静态变量,即只读变量,不可被修改。
在链接多个object文件时,链接器会将含有同名setcion的信息放在单个section的可执行文件。比如当链接多个obj文件时,所有obj文件中的.text会被分到同一个组,并且被放置到一个同样加做.text section中的可执行文件中。看下图:

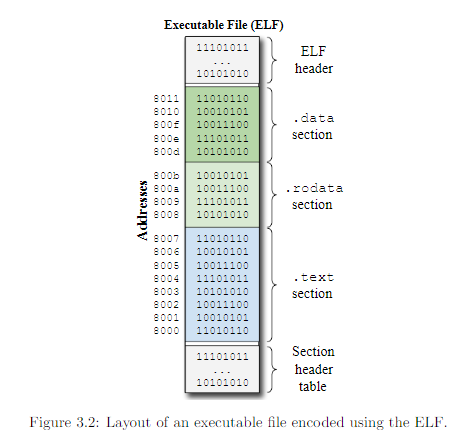
.text被映射到8000~8007,同时,.data被映射到800d~8011。
默认情况下,GNU 汇编工具会将所有信息添加到 .text 部分。要指示汇编程序将已汇编的信息添加到其他部分,请执行以下操作,编译器会使用.setcion secname指令。指令指示汇编器将下面装配信息到secname的section(段)中,。来看看例子是怎么将.text放一起,变量放在.data。
01 .section .data
02 x: .word 10
03 .section .text
04 update_x:
05 la t1, x
06 sw a0, (t1)
07 ret
08 .section .data
09 y: .word 12
10 .section .text
11 update_y:
12 la t1, y
13 sw a0, (t1)
14 ret 第一行的section .data指示汇编器开始添加.data``section从那个位置开始。而第二行则是声明的同时还初始化该变量。第三行,section .text指示汇编器将下面的系统添加到.text``section,因此update_x标签会被连接到.text段中且接下来的三条指令也会被添加到.text段。第八行,section .data又指示后面的指令会被添加到.data段,因此,y变量,会被放在x后面。接着,.section .text(第10行)指示接下来的信息添加到.text。最后update_y标签与其后面的指令会被添加到.text段。
假设之前的代码存在prog.s中,使用命令来看看:
$ riscv64-unknown-elf-as -march=rv32im prog.s -o prog.o
$ riscv64-unknown-elf-objdump -D prog.oprog.o: file format elf32-littleriscv
Disassembly of section .text:
00000000 <update_x>:
0: 00000317 auipc t1,0x0
4: 00030313 mv t1,t1
8: 00a32023 sw a0,0(t1) # 0 <update_x>
c: 00008067 ret
00000010 <update_y>:
10: 00000317 auipc t1,0x0
14: 00030313 mv t1,t1
18: 00a32023 sw a0,0(t1) # 10 <update_y>
1c: 00008067 ret
Disassembly of section .data:
00000000 <x>:
0: 000a c.slli zero,0x2
...
00000004 <y>:
4: 000c 0xc
... 请注意,由update_x 和update_y标签表示的程序例程以及程序指令都位于 .text 部分,而由 x 和 y 标签以及 32 位值 000a 和 000c 表示的全局变量则位于 .data 部分。同时我们还注意到,每个section的起始位置被分配为0000000。然而,因为数据指令存储在同一个地址,但我们不能将这些变量与指令存到主存的同一位置。链接器通过重定址来解决这个问题,这样使得指令和数据分配到无冲突的地址。来使用下面命令看看:
$ riscv64-unknown-elf-ld -m elf32lriscv prog.o -o prog.x
$ riscv64-unknown-elf-objdump -D prog.xprog.x: file format elf32-littleriscv
Disassembly of section .text:
00010074 <update_x>:
10074: 00001317 auipc t1,0x1
10078: 01c30313 addi t1,t1,28 # 11090 <__DATA_BEGIN__>
1007c: 00a32023 sw a0,0(t1)
10080: 00008067 ret
00010084 <update_y>:
10084: 80418313 addi t1,gp,-2044 # 11094 <y>
10088: 00a32023 sw a0,0(t1)
1008c: 00008067 ret
Disassembly of section .data:
00011090 <__DATA_BEGIN__>:
11090: 000a c.slli zero,0x2
...
00011094 <y>:
11094: 000c 0xc
...可以看到:10074~1008f是.text段,10090~10097是.data段。
**注:**有些操作系统配置硬件使用写保护.text和.rodata段,因此,数据最好不要放在里面。另外,有些操作系统会让CPU禁止执行不是.text的代码段,所以代码最好放在.text中。
可执行与object文件
可执行和链接格式(ELF)被多个基于 Linux 的操作系统用于编码对象文件和可执行文件。尽管对象文件和可执行文件都可能包含机器代码,而且都可以使用 ELF 进行编码,但它们在以下方面存在差异:
- 如第 3.3 节所述,
object上的地址并非最终地址,不同部分的元素可能被分配到相同的地址。因此,不同部分的元素可能不会同时位于主内存中。 object文件可能存在未解析的符号,它需要后期链接器的进一步处理。object会有一个重定址表,它使得指令和数据可以在链接时重定址。而在Executable文件中的地址就是最终值。object文件没有一个entry point
章节4
汇编语言
汇编有以下4个主要元素组成:
- **注释:**在汇编构建时会被丢弃,仅仅是记录一些信息而已。
- **标签(Label)😗*早在前面章节就讨论过,标签作为一个表示程序位置的标记。常常在名字后面跟上一个
":",它能够插入到汇编程序中,所以它可以被汇编指令或者命令调用,比如:汇编指令。 - **汇编指令(Assembly instruction)😗*汇编指令可以被汇编器转换为机器码的。他常常被编译成一个方便记忆和一些列成为操作数的参数组成的字符串。比如说:
addi a0, a1, 1字符串就包含了addi助记符和三个操作数a0, a1, 1。 - **汇编命令(Assembly directives)😗*汇编命令是用来搭配汇编处理过程的命令,它被汇编器解释。比如:
.word 10命令指示汇编器组装32-bit的值到程序中。汇编命令常常被编码成一个含有"."前缀的和它的参数的字符串。
注释没什么作用在汇编过程,并且会被转化为空白字符,然后丢弃。假设<label>、<instruction>和<directive>分别表示标签,指令,命令。那么来看看下面的语法格式:
PROGRAM -> LINES
LINES -> LINE [‘\n’ LINES]
LINE -> [<label>] [<instruction>] |
[<label>] [<directive>]前面正则表达式的前两条规则表明,汇编程序由一行或多行组成,这些行以行结束符(即"\n")分隔。最后一条规则意味着:
- 一行可能会会是空的。注意
<label>、<instruction>和<directive>是可选的。 - 一行可能只有标签
- 一行可能只有标签和汇编指令
- 一行可能只有一个汇编指令
- 一行可能只有标签和汇编命令
- 一行可能只有汇编命令
来看看RV32I的汇编代码示例:
1 x:
2
3 sum: addi a0, a1, 1
4 ret
5 .section .data
6 y: .word 10下面的RV32I汇编代码包含错误汇编的示例。第一行包含两个标签,第二行包含后跟标签的指令(注意,当两者位于同一行时,标签必须位于指令之前)。第三行包含两个指令,第四行包含两个汇编命令,但是,只允许一个指令或一个命令在一行之中。第五行包含一个后跟标签的汇编命令,但是,当两者位于同一行时,标签必须位于命令之前。第六行,包含了一条指令和命令。第七行则是有一条错误的命令。
/*错误示例*/
1 x: z:
2 addi a0, a1, 1 sum:
3 li a0, 2 li a1, 1
4 .word 10 .word 20
5 .word 10 y:
6 addi a0, a1, 1 .word 12
7 .sdfoiywer 1下面的RV32I汇编代码同样是错误的,因为所有的元素是一个单指令,它的助记符和操作数必须在同一行,同样的汇编命令也是一样。
/*错误示例*/
addi
a0, a1, 1GNU汇编工具实际上是一个汇编器系列,它包括多个 ISA(包括 RV32I ISA)的汇编器。尽管每个 GNU 汇编程序所使用的汇编语言不同(通常是由于汇编指令不同,而汇编指令的设计与 ISA 上的机器指令类似),但它们中的大多数都具有相同的注释和标签语法,以及相同的汇编指令语法。从这个意义上说,一旦学会了一种汇编语言,学习新的汇编语言就会变得很容易。
在这本书中,我们将重点介绍由gnu汇编工具解释的RV32I汇编语言。下面几节将讨论用于gnu汇编工具的RV32I汇编程序中的注释、标签、汇编指令和汇编指令的语法
**ISA(Instruction Set Architectur)😗*指令集体系结构,我们所学的RISC-V就是一种指令集体系架构。
注释
- 单行注释
1 x: .word 10 # This is a comment
2 foo: # My special function
3 addi a0, a1, 1 # Adds one to a1 and store on a0 #
4 # This is # another # comment ## #- 多行注释
1 sum1:
2 /* This
3 is
4 a
5 multi-line
6 comment.
7 */
8 addi a0, a1, 1
9 ret汇编指令
汇编指令是一种会被汇编器转换为机器指令的指令。它通常被编码成一个助记符和一些列的被叫做操作数的参数。比如:addi x10, x11, x12,这个会被编码成17个字节,它会被汇编器转换为相应的机器码:0x00c58533。
一个****在ISA中没有相应的机器码,但它可被汇编器自动的转化为一到多条指令来达到相应的效果。比如:无操作,可以使用伪指令nop,该伪指令会被翻译成:addi x0, x0, 0。另外一个例子就是mv,一条复制一个寄存器值到另外一个寄存器的伪指令,使用mv a5, a7就会被翻译为addi a5, a7, 0,把a7加上0,然后把结果传送到a5。
附录A展示的了RV32I的汇编指令列表,并且,在Part II中会讨论这些如何使用这些指令完成编程结构,如:条件,循环,函数等。
一个操作数可能包括以下情况:
- 寄存器名:一个寄存器名字在
RV32I众多寄存器中的一个,RV32I有0~31个寄存器叫做:x0,x1...x31。同时这些寄存器还有别名:a0,t1, ra等等。附录A里面有列出他们的别名 - 立即数:一个立即数会不变的编码进入指令中的部分bit中。
- 符号名(symbol name):符号表中的符号名会被它们各自的值替换,在汇编和链接时。例如,它们可以标识由用户明确定义的符号或由汇编器自动创建的符号,如为标签创建的符号。他们的值会被编入机器指令中的几个
bit。
立即数
立即数在汇编语言中表现为一串字符数字,串的开头以0x或者0b分别表示十六进制和二进制。八进制的数则是使用0开头。而十进制则是使用1~9表示。
而字符表现为使用单引号('x')引起来的会被转化为ascii数值。比如:'a'则会被转为9,来看看下面的例子:
1 li a0, 10 # loads value ten into register a0
2 li a1, 0xa # loads value ten into register a1
3 li a2, 0b1010 # loads value ten into register a2
4 li a3, 012 # loads value ten into register a3
5 li a4, ’0’ # loads value forty eight into register a4
6 li a5, ’a’ # loads value ninety seven into register a5而负整数则使用'-'表示:
1 li a0, -12 # loads value minus twelve into register a0
2 li a1, -0xc # loads value minus twelve into register a1
3 li a2, -0b1100 # loads value minus twelve into register a2
4 li a3, -014 # loads value minus twelve into register a3
5 li a4, -’0’ # loads value minus forty eight into register a4
6 li a5, -’a’ # loads value minus ninety seven into register a5符号名
程序符号是与数值相关联的 "名称","符号表 "是将每个程序符号映射到其数值的数据结构。label会被自动的转换为符号。另外,程序员或者编译器会精准的直接通过.set创建符号。
符号名的定义限制在:字符、数字、下划线(_)。注意,第一个字符不能是数字。正确示范如下:x,var1,z123,_x,_,_1。
下面的代码就展示了使用符号名作为操作数(第4行与第5行)。.set(第1行)直接创建了max_temp符号并且将100与它联系起来。load(加载)指令将max_temp的值加载到寄存器t1中。分支命令“小于等于”(ble)会在a0的值小于或等于t1时跳转到代码的temp_ok符号位置(该位置由标签temp_ok自动定义)。
1 .set max_temp, 100 # Set the max_temp limit
2
3 check_temp: # check_temp routine
4 li t1, max_temp # Loads the max_temp limit into t1
5 ble a0, t1, temp_ok # If a0 <= max_temp, then ok
6 jal alarm # Else, invokes the alarm routine
7 temp_ok:
8 ret # Returns from the routine标签(labels)
如第 3.2.1 节所述,标签是代表程序位置的 "标记。它能够直接的被指令和汇编命令直接使用并且被翻译成地址,在汇编和链接过程。
GNU汇编器接受两种类型的标签:符号和数字标签。
- 符号标签:作为符号存储在符号表中,通常用于标识全局变量和例程。符号标签由标识符和**冒号(:)**组成。标识符与符号名的语法相同,如上一节所述。下面的代码包含两个符号标签:
age:和getage:
1 age: .word 42
2
3 get_age:
4 la t1, age
5 lw a0, (t1)
6 ret- 数字标签:数字标签由一个十进制数字和一个冒号(:)组成。它们用于本地引用,不包含在可执行文件的符号表中。此外,它们还可以在同一个汇编程序中重复引用。 对数字标签的引用包含一个
"suffix",表示引用的数字标签是位于引用之前('b' suffix)还是之后('f' suffix)。这段代码有一个符号标签(pow)和两个数字标签(均命名为 1:)。位于第 7 行的第一个数字标签标志着一个循环指令序列的开始。位于第 11 行的跳转指令会跳回到这个标签--注意引用1b,它指的是位于引用之前的数字标签"1"。位于第 12 行的第二个数字标签标记了位于循环之后的指令的位置,即必须在循环结束后执行的指令。
1 # Pow function -- computes a^b
2 # Inputs: a0=a, a1=b
3 # Output: a0=a^b
4 pow:
5 mv a2, a0 # Saves a0 in a2
6 li a0, 1 # Sets a0 to 1
7 1:
8 beqz a1, 1f # If a1 = 0 then done
9 mul a0, a0, a2 # Else, multiply
10 addi a1, a1, -1 # Decrements the counter
11 j 1b # Repeat
12 1:
13 ret位置计数器与汇编处理
该章节叙述较为繁琐,看原文即可。
汇编命令(directives)
汇编命令是一种命令被用来控制编译器。比如,
.section、.data直接指示汇编器切换到.data段(section)作为当前的工作区。另外,通过.word 10直接指示汇编器将一个32-bits的数值(10)添加到工作区(.data)。汇编通常被编译成一串包含命令名和参数的字符串。在GNU汇编器中,命令名包含一个点(
.)前缀。下一个章节会讨论一些常用的汇编命令在编程中的用法。
在程序中添加数值
下表就是一个使用汇编命令添加数值到程序中的表:

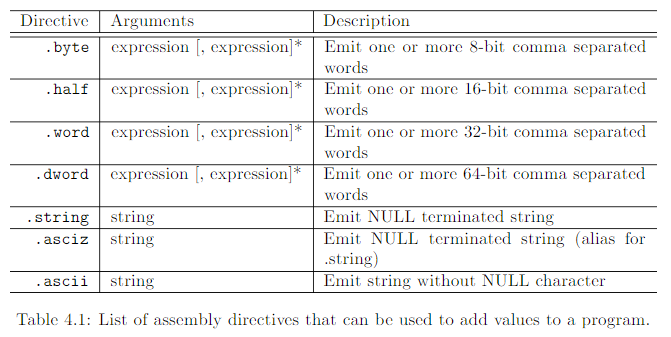
上表所有的命令都是添加数值到活动的section。.byte,.half,.word,.dword命令是添加一个或者多个数值到活动section中。它们的参数可以用立即数(如第 4.3 节所述)、符号(在组装和连接过程中用其值替换)或两者结合的算术表达式来表示。下面的代码是这些命令参数的有效使用。第1行的.byte添加了4个8-bit的数值到活动section中。第2行.word命令添加一个用x表示的32-bit值到活动section中。注意,与符号 x 相关的值就是分配给标签 x: 的地址。第3行的.word添加一个32-bit数值到活动区,然而,在这样的情况下,值的结算结果是将符号 y 的相关值(即分配给标签 y 的地址)加上 4。
1 x: .byte 10, 12, ’A’, 5+5
2 y: .word x
3 z: .word y+4
4 i: .word 0
5 j: .word 1.string、.asciz、.ascii命令添加一串字符串到活动section。正如前面章节讨论的一样,字符串是一个有序的字符数组编码而成。.string和.asciz指令还会在字符串后添加一个值为0的额外字节。它们有助于在程序中添加以 NULL 结尾的字符串。
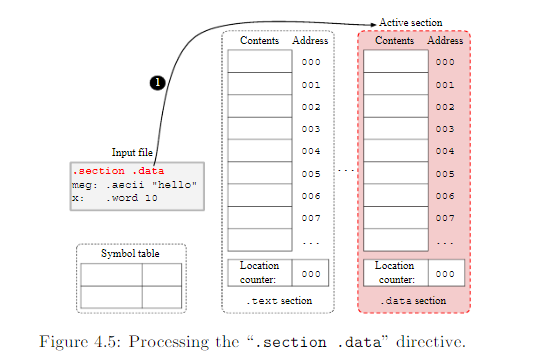
为了阐明前面命令的用法,让我们组装(assemble)下面的代码到.data段。
1 .section .data
2 msg: .ascii "hello"
3 x: .word 10正如4.6节(位置计数器与汇编处理章节)讨论的一样,GNU编译器一开始会清空section的内容和符号表,并且初始化他们为0,然后选择.text段作为活动段。接着,它开始处理输入文件。第一个汇编元素在输入文件时.section .data命令,这个命令指示汇编器让.data成为活动段。下图即是:

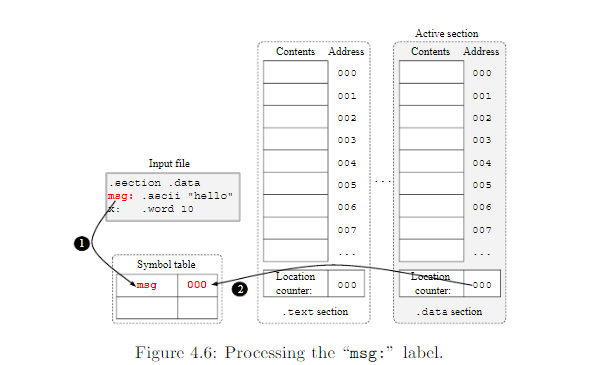
下一个元素就是标签msg:。在这种情况下,汇编器(1)注册名叫msg的符号到符号表中,并为它分配一个地址从当前的location counter中。下图即是:

在我们代码中下一个元素是:.ascii "hello"命令,它告诉汇编器添加一串字符串到活动section中。假设我们的输入文件通过ASCII标准来编码,汇编器(1)通过标准ASCII将一串字节编码,(2)添加这些字节到下一个活动section的空地址,接着(3)更新location counter的值。,下图即是:

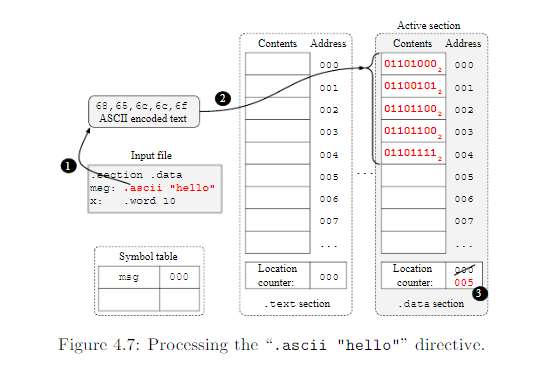
下一个元素是标签名为x:的元素。在这种情况下,汇编器会将该符号名为x的符号加入到符号表中,并且通过location counter为其分配一个有效地址(从活动section)。
最后,最后一条元素:.word 10命令,它指示汇编器添加一个32-bit的值到活动section。在这样的情况下,汇编器(1)编码一个32-bit的值成一串4字节的组,(2)储存这些数据到活动section中使用小端模式,并且更新location counter的值。来看下图:


.section命令
正如在第3.3节中讨论的一样,汇编文件,obj文件,执行文件他们会被组织在section中。另外,GUN汇编器会默认的添加信息到.text中。为了指示汇编器添加汇编信息到另一个section中,编程人员或者编译器可能会使用.section secname命令。该命令会使secname段作为活动段,在这条命令后,所有的信息都会被汇编器添加到secnamesection中。
程序指令提倡放到.text中,而只读数据建议放到.rodata中。另外,初始化的全局变量放到.data中,而未初始化的区局变量则放到.bss段中。
下面的代码演示的是如何放指令到.text中,和放编程变量到.data和.rodata中。
1 .section .text
2 set_x:
3 la t1, x
4 sw a0, (t1)
5 ret
6 get_msg:
7 la a0, msg
8 ret
9 .section .data
10 x: .word 10
11 .section .rodata
12 msg: .string "Assembly rocks!"**注意:**RV32I GNU也包括上的.text,.data,.bss命令的其他名字:.section .text,.section .data,.section .bss.
在.bss段中分配变量
.bss段中的变量被指定存放为初始化的数据。这些变量被存放在内存中,但是他们并不需要在程序运行是被loader进行初始化。所以 ,他们的初始化的值不需要被保存在可执行文件或者obj文件。
因为可执行文件与obj文件的.bss段中不存放任何信息,所以GNU 汇编程序不允许汇编程序向.bss部分添加数据。为了说明这种情况,让我们思考一下下面的代码。
1 .section .bss
2 x: .word 10
3 .section .text
4 set_x:
5 la t1, x
6 sw a0, (t1)
7 ret这个代码试图使用.word 10命令来向.bss段中添加32-bit的值。然而,当处理该.word 10命令时,GNU汇编器会停止,并且发出如下的错误信息:
1 $ riscv64-unknown-elf-as -march=rv32im data-on-bss.s -o data-on-bss.o
2 data-on-bss.s: Assembler messages:
3 data-on-bss.s:2: Error: attempt to store non-zero value in section ‘.bss’要在 .bss 部分分配变量,需要声明一个标签来标识变量,并将 .bss 位置计数器按变量所需的字节数提前,以便在其他地址上分配更多变量。
.skip N 指令是一种将位置计数器提前N个单位的指令,可用于为 .bss 部分的变量分配空间。下面的代码显示了如何将.skip指令与标签相结合,为 x、V 和 y 这三个不同的变量分配空间。在这个例子中,程序为变量 x 和 y 分配了 4 字节的空间,为变量V分配了 80 字节的空间。因此,标签 x、V 和 y 将分别与地址 0x0、0x4 和 0x54 相关联。
1 .section .bss
2 x: .skip 4
3 V: .skip 80
4 y: .skip 4**注意:**有些系统在将程序载入主内存执行时,会将 .bss 部分专用的内存字初始化为零。不过,程序员不应认为 .bss 部分的变量会被初始化为 0。
其他
CPU内部寄存器

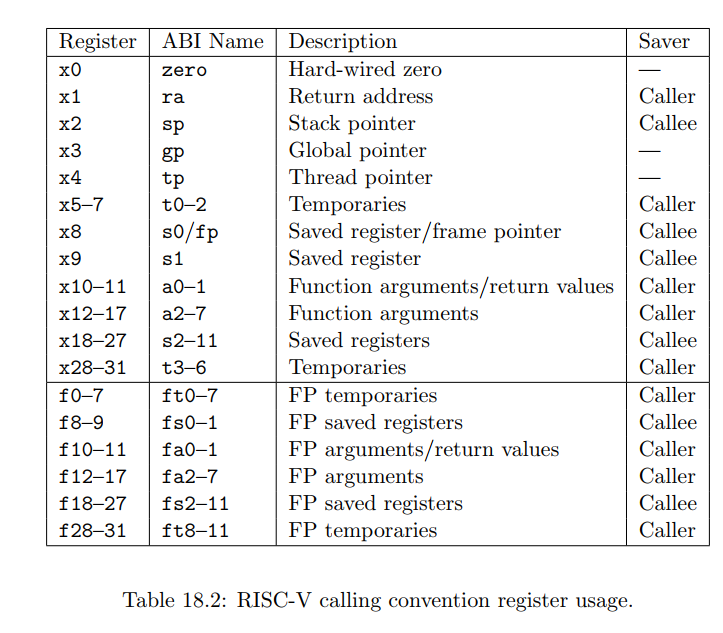
| 寄存器 | ABI名称 | 描述 | 保存者 | 其他 |
|---|---|---|---|---|
| x0 | 0 | 硬件电路上的0 | - | 读出来的值永远为 0 |
| x1 | ra | 返回地址 | 调用者 | |
| x2 | sp | 栈指针 | 被调用者 | |
| x3 | gp | 全局指针 | - | |
| x4 | tp | 线程指针 | - | |
| x5-x7 | t0-2 | 临时变量寄存器 | 调用者 | |
| x8 | s0/fp | 保存寄存器0/栈帧指针 | 被调用者 | |
| x9 | s1 | 保留存存器1 | 被调用者 | |
| x10-x11 | a0-a1 | 函数参数0到1/返回值 | 调用者 | |
| x12-x17 | a2-a7 | 函数参数2到7 | 调用者 | |
| x18-x27 | s2-s11 | 保存寄存器2到11 | 被调用者 | |
| x28-x31 | t3-t6 | 临时变量寄存器3到6 | 调用者 | |
| f0-f7 | ft0-ft7 | FP 临时 | 调用者 | |
| f8-f9 | fs0-fs1 | FP 保存寄存器 | 被调用者 | |
| f10-f11 | fa0-fa1 | FP 参数/返回值 | 调用者 | |
| f12-f17 | fa2-fa7 | FP 参数 | 调用者 | |
| f18-27 | fs2-fs11 | FP 保持寄存器 | 被调用者 | |
| f28-f32 | ft8-ft11 | FP 临时 | 调用者 | |
| pc | pc | 程序计数器 |
贡献者
 Px
Px